NTFS Index Attributes
NTFS Index Attributes
Now that we have described the general concept of B-trees, we need to describe how they are implemented in NTFS to create indexes. Each entry in the tree uses a data structure called an index entry to store the values in each node. There are many types of index entries, but they all have the same standard header fields, which are given in Chapter 13. For example, a directory index entry contains a few header values and a $FILE_NAME attribute. The index entries are organized into nodes of the tree and stored in a list. An empty entry is used to signal the end of the list. Figure 11.18 shows an example of a node in a directory index with four $FILE_NAME index entries.
Figure 11.18. A node in an NTFS directory index tree with four index entries.
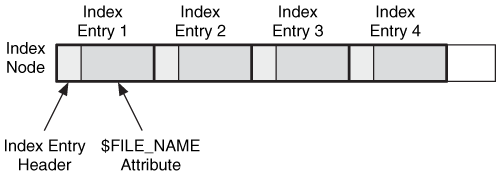
The index nodes can be stored in two types of MFT entry attributes. The $INDEX_ROOT attribute is always resident and can store only one node that contains a small number of index entries. The $INDEX_ROOT attribute is always the root of the index tree.
Larger indexes allocate a non-resident $INDEX_ALLOCATION attribute, which can contain as many nodes as needed. The content of this attribute is a large buffer that contains one or more index records. An index record has a static size, typically 4,096 bytes, and it contains a list of index entries. Each index record is given an address, starting with 0. We can see this in Figure 11.19 where we have an $INDEX_ROOT attribute with three index entries and a non-resident $INDEX_ALLOCATION attribute that has allocated cluster 713, and it uses three index records.
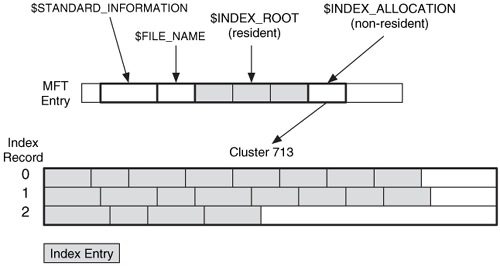
An $INDEX_ALLOCATION attribute can have allocated space that is not being used for index records. The $BITMAP attribute is used to manage the allocation status of the index records. If a new node needs to be allocated for the tree, $BITMAP is used to find an available index record; otherwise, more space is added. Each index is given a name and the $INDEX_ROOT, $INDEX_ALLOCATION, and $BITMAP attributes for the index are all assigned the same name in their attribute header.
Each index entry has a flag that shows if it has any children nodes. If there are children nodes, their index record addresses are given in the index entry. The index entries in a node are in a sorted order, and if the value you are looking for is smaller than the index entry and the index entry has a child, you look at its child. If you get to the empty entry at the end of the list, you look at its child.
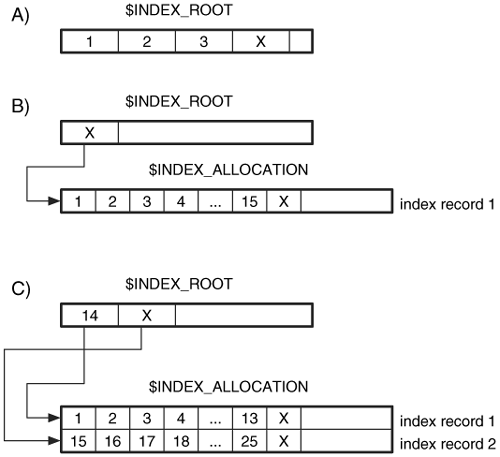
Let us go over some examples. Consider an index with three entries that fit into $INDEX_ROOT. In this case, only a $INDEX_ROOT is allocated, and it contains three index entry data structures and the empty entry at the end of the list. This can be seen in Figure 11.20(A). Now consider an index with 15 entries, which do not fit into an $INDEX_ROOT but fit into an $INDEX_ALLOCATION attribute with one index record. It can be seen in Figure 11.20(B). After we fill up the index entries in the index record, we need to add a new level, and we create a three-node tree. This scenario is shown in Figure 11.20(C). This has one value in the root node and two children nodes. Each child node is located in a separate index record in the same $INDEX_ALLOCATION attribute, and it is pointed to by the entries in the $INDEX_ROOT node.
Figure 11.20. Three scenarios of NTFS indexes, including A) a small index of three entries, B) a larger index with two nodes and 15 entries, and C) a three-node tree with 25 entries.
REF- File System Forensics Analysis (BRAIN CARRIER) (2005)
Comments